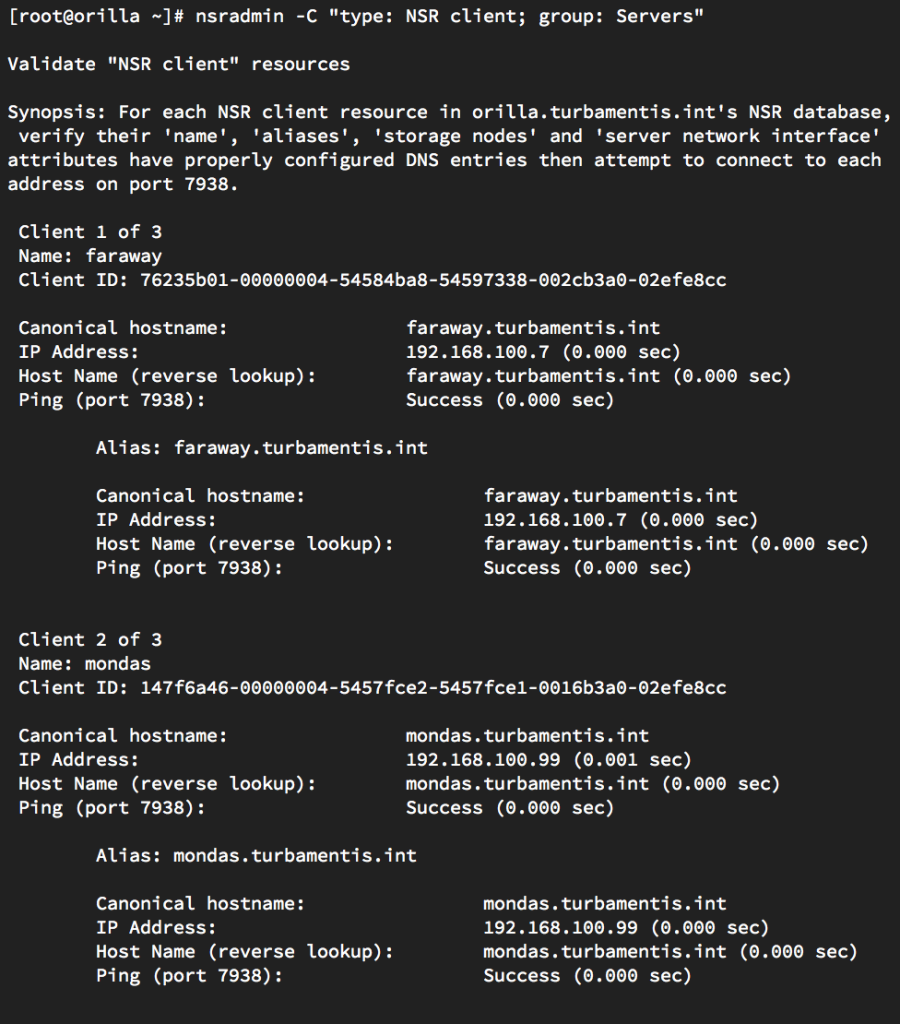
Introduction![Data Domain]()
It’s true there are some data types that broadly aren’t suitable to sending to Data Domain – any more than they’re suitable for sending to any other deduplication appliance or system within any environment. Large imaging data and video files will yield minimal deduplication except over successive backups (assuming static data), and compressed and/or encrypted data aren’t all suited either.
But the majority of data within most organisations is suited for writing to Data Domain systems.
Years ago when EMC purchased Data Domain, I don’t think anyone anticipated just what they had in mind for the appliance. I certainly didn’t – and I’d been involved in the backup industry for probably 15 years at that point. Deduplication had been kicking around for several years, but it hadn’t been mainstreamed to the degree EMC has achieved.
The numbers practically speak for themselves. Data Domain represents an overwhelming lions share of the deduplication appliance space – but I’m not going to quote numbers here. I’m going to talk about the architectural vision of Data Domain.
As a target-only appliance, Data Domain represents considerable advantage to any business that deploys it, but that’s just the tip of the iceberg. The real magic happens when we start to consider the simple fact that a Data Domain is not a dumb appliance. EMC have chosen to harness the platform to deliver maximum bang for buck for any company that walks down that path.
May the source be with you
Target based deduplication works brilliantly for drastically reducing the total amount of data stored, but it still results in that data being sent. Avamar demonstrates this overwhelmingly – its source based deduplication backup process is unbelievably efficient and powerful and is a powerfully attractive choice for many businesses, particularly those in the xaaS industry.
Data Domain’s Boost functionality extends its deduplication technology up to the origin of the data. For products like NetWorker, Avamar and VDP/VDPA, this goes right to the source. (For third party products such as NetBackup, it covers the media servers.)
If Boost had stopped at NetWorker and Avamar integration, it would have been a remarkably powerful efficiency hook for many businesses, but there’s more power to be had. The extension of Data Domain Boost to include support for enterprise applications such as Oracle, SQL Server, SAP, etc., provides unparalleled extensibility in the backup space to organisations. It also means that businesses who have deployed other backup technologies but leverage the power of Data Domain deduplication in their data protection strategy can get direct client deduplication performance for what is often their most mission critical systems and applications.
I’m the first to admit that I’ve spent years trying to convince DBAs to hand over control of their application backups to NetWorker administrators. It’s a discussion I’ve won as much as I’ve lost, but the Data Domain plugins for databases have proven one key lesson: when I’ve ‘lost’ that discussion it’s not been through lack of conviction, but through lack of process. DBAs are all for efficiencies in the backup process, but given the enterprise criticality of databases in so many organisations, much of the push back on backup centralisation has been from a lack of control of the process.
The Boost application plugins get past that by allowing a business to make the decision to integrate their application backups into centralised backup storage while allowing for highly granular control of the backup process through the agreed and trusted scheduling methods that offer considerably more granular and flexible controls. Backup products offer scheduling, of course, but they’re not meant to be the bees knees of scheduling that you’ll find in products devoted solely to that purpose. That’s what DBAs have mostly resisted. (This, for what it’s worth, is the difference between app-centric aspects to backup and recovery and a decentralised backup ‘system’.)
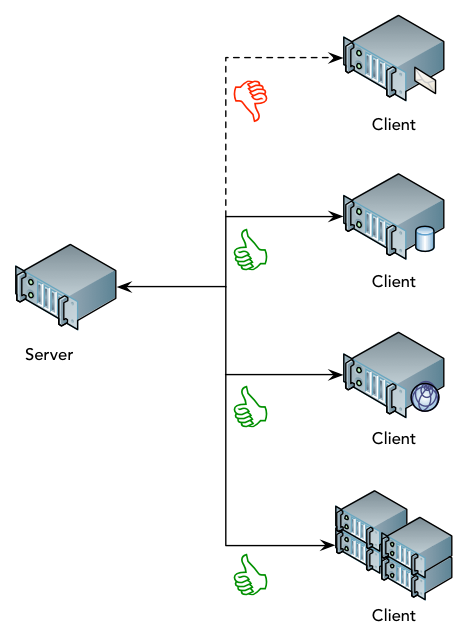
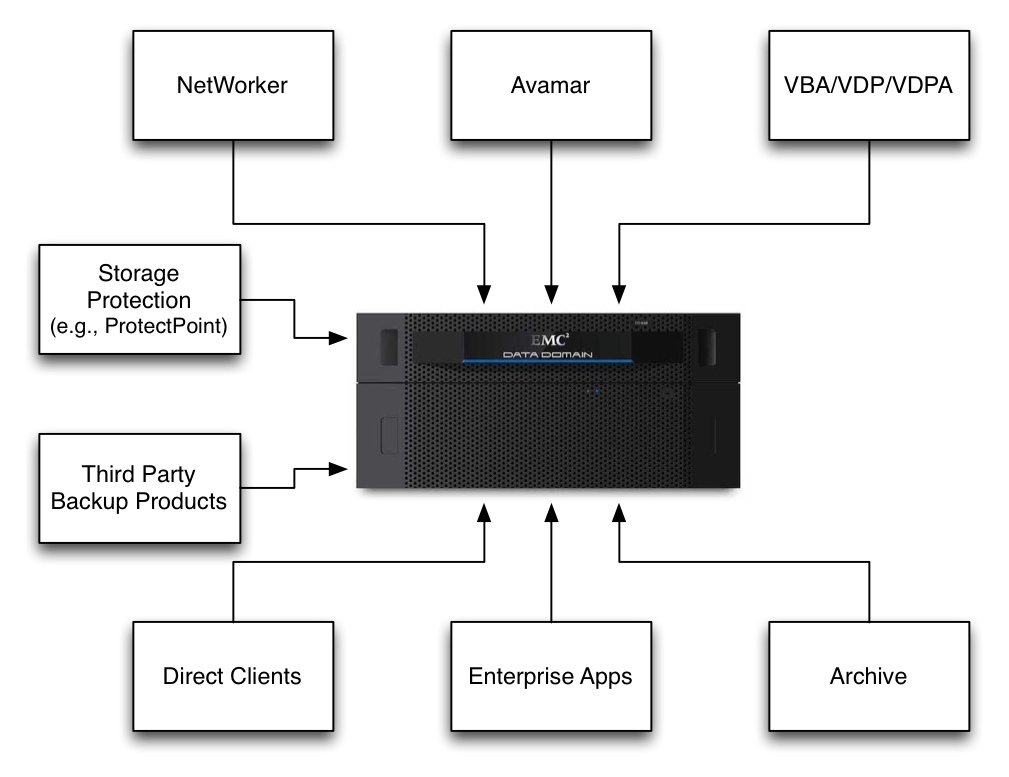
Here’s where we’re at with Data Domain – it now sits at a nexus in the Data Centre for data protection and nearline archival storage:
![May the source be with you]()
(Yes, it’s even very well suited for archival workloads.)
NetWorker, Avamar, VDP/VDPA, Client Direct, Enterprise Apps – I could go on – Data Domain sits at the centre ready to receive the data you want to send to it.
But that diagram isn’t quite complete. To truly get the maximised efficiency out of Data Domain, the picture really should look more like this:
![Protecting the Protection]()
That’s right – logically, a Data Domain solution will have at least two Data Domains in it, so that whatever you’re protecting via the Data Domain will itself be protected. Now, by itself, Data Domain offers excellent protection for the data you’re storing, but unlike what most people think of on this front, RAID-6 storage protection is just the tip of the iceberg. RAID-6 is nice – it protects you from two drive failures at any point. On top of that though, you have the Data Invulnerability Architecture that you’ll hear EMC folks talk about quite regularly – that’s the magic sauce. The Data Domain doesn’t just sit there storing your data: it stores it, it checks it, it reads it again, and it checks it as part of regular verification. (If you want to compare it to tape, imagine having a tape library big enough to store every tape you keep for retention and constantly sits there loading all the tapes and confirming all the data can be read back.)
But we all know in the data protection world that you still need that added protection of keeping a second copy of that data, regardless of whether that’s for compliance or for true disaster protection. In terms of absolute efficiency, the absolute best way you’ll get a secondary copy of that data is via the global deduplicated replication offered between two Data Domains. (For what it’s worth, that’s where some companies make the mistake of deploying tape as their secondary copy from an original backup target of Data Domain: what’s the point of deploying efficient deduplication if the first thing you’re going to do is rehydrate all the content again?)
Aside: Coming back to encryption and compression
Earlier I said that compressed and encrypted workloads aren’t necessarily suited to Data Domain. That’s true, but that usually reflects an opportunity to revisit the process and thinking behind those workloads.
Compression is typically used in a data streaming activity for data protection because of a requirement to minimise the amount of data going across the network. Boost eliminates that need by doing something better than compression at the client side – deduplication. Deduplication doesn’t just compress the original data, but it substantially reduces the original data by not even bothering to send data that already exists at the target. For instance, if I turn my attention to Oracle, the two most common reasons why DBAs will create compressed Oracle backups are:
(a) They’re writing them to primary storage and trying to minimise the footprint, or
(b) They’re writing them to NAS or some other form of network storage, and want to minimise the amount of data sent over busy links.
Both of those are squarely addressed by Data Domain:
- For (a), the footprint is automatically reduced by writing it in uncompressed format to the Data Domain. It handles the deduplication automatically. In fact, it’ll be a lot more space efficient than say, the three most recent database backups being written to Tier-1/Primary storage.
- For (b), because only unique data is sent over the network, and that data is compressed by Boost before it’s sent over the network, you’re still ending up with a more efficient network transfer than writing a compressed copy over the network.
Encryption might be considered a trickier subject, but it’s not really. There’s two types of encryption a business might require – at rest, or in-flight. Data Domain has supported encryption at rest for quite a long time, and the recent support for in-flight encryption has completed that piece of the puzzle. (That in-flight encryption is integrated in such a way that it still allows for local/source deduplication and associated pre-send compression, too.)
What all this means
When EMC first acquired Data Domain, they acquired a solid product that had already established excellent customer trust built from high reliability and performance. While both of those features have continued to grow (not to mention capacity … have you seen the specs on the Data Domain 9500?), those features alone don’t make for a highly extensible product (just a reliable big bucket of storage). The extensibility comes from the vertical integration right up into the application stack, and the horizontal integration across a multitude of use cases.
Last year’s survey results revealed a very high number of NetWorker environments leveraging Data Domain within their environment, but what we see if we step back a little bit from a single-product focus is that Data Domain is a strategic investment in the enterprise, able to be utilised for a plethora of scenarios across the board.
So there’s two lessons – one for those with Data Domain already, and one for those preparing to jump into deduplication: if you’ve already got Data Domain in your environment, start looking at its integration points and talking to either EMC or your supplier about where else Data Domain can offer synergies, and if you’re looking at deploying, keep in mind that it’s a highly flexible appliance capable of fitting in to multiple workloads.
Either way, that’s how you achieve an excellent return on investment.